We propose Anypose-to-Anypose (AP2AP), a task-agnostic sim-to-real learning formulation for dexterous manipulation. AP2AP abstracts manipulation as directly transforming an object from an arbitrary initial pose to an arbitrary target pose in 3D space, without assuming task-specific structure, predefined grasps, or motion primitives. Conditioned on point tracks, we train our AP2AP policy on over 3,000 objects in simulation, and directly deploy the learned policy to real-world dexterous manipulation tasks without any real-robot data collection or policy fine-tuning.
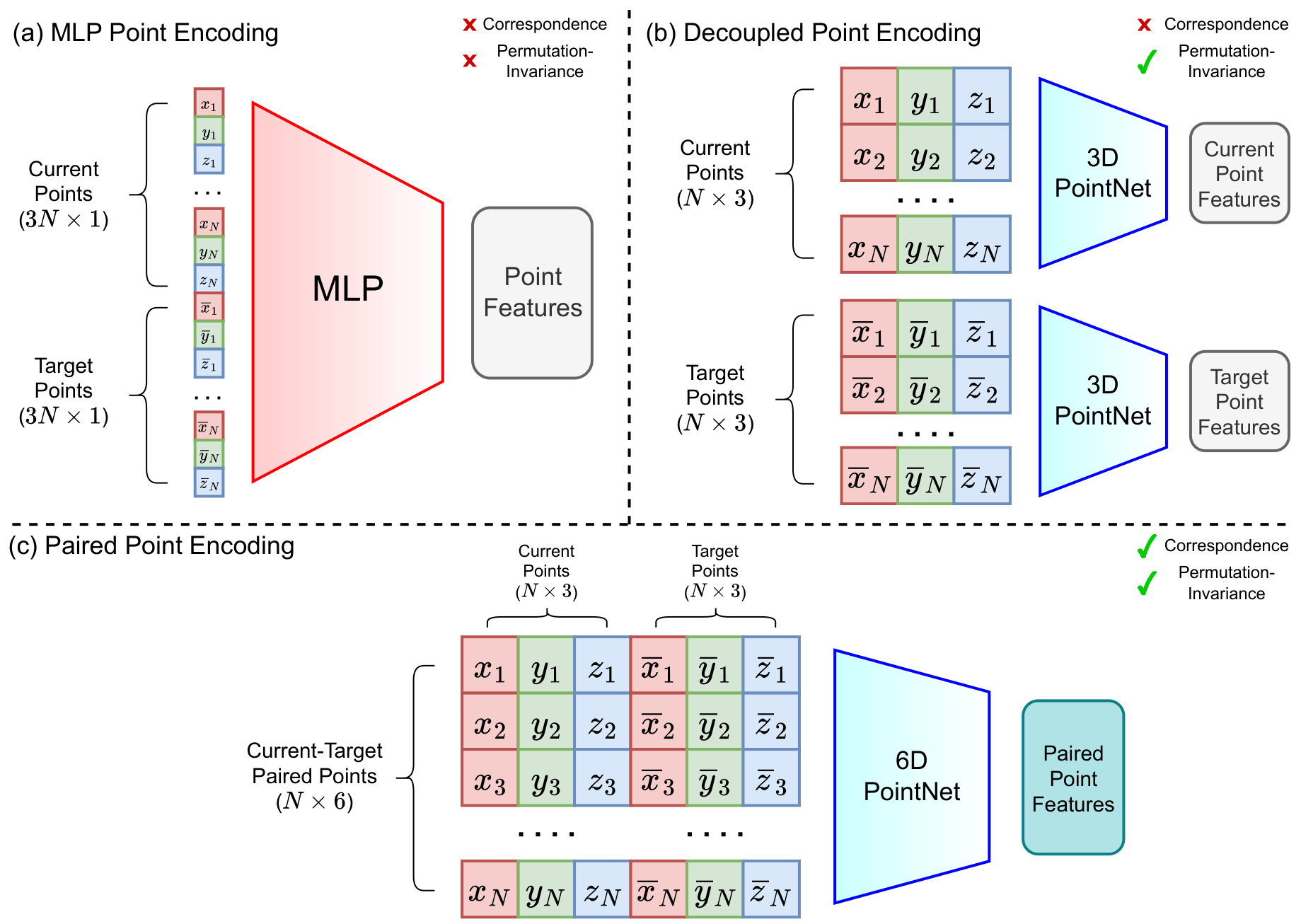
Comparison between our Paired Point Encoding with other representations. Point features encoded from our Paired Point Encoding keep correspondence and permutation-invariance of the current and target object points, which shows better performance for policy learning.
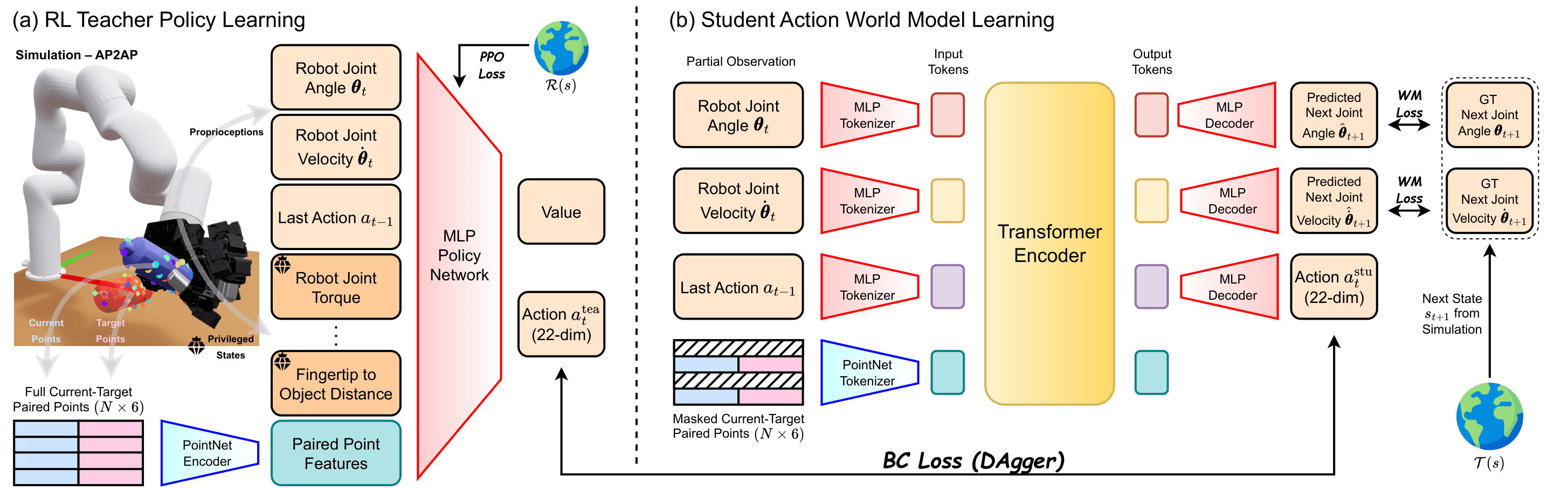
Overview of our Dex4D teacher and student network architectures. (a) We first learn a teacher policy via RL with privileged states and full points sampled on the whole object, leveraging our proposed Paired Point Encoding representation. (b) Given partial observation, i.e., robot proprioception, last action, and masked paired points, we distill from the teacher and learn a transformer-based student action world model that jointly predicts actions and future robot states.